Side-by-side comparison of Self-Forcing baseline vs. Sparse Forcing (Ours).
"In super slow motion, a friendly panda bear sits at a cozy café table in Paris. The panda is wearing a small, stylish beret and is seated comfortably in a chair. It holds a steaming cup of coffee delicately with both paws, sipping from a straw inserted into the cup. The panda's black eyes are focused on the cup with a curious yet relaxed expression. The café background showcases elegant Parisian decor, including vintage posters and soft lighting, with other patrons subtly visible in the periphery. The scene captures the panda's gentle movements and the delicate steam rising from the coffee in a close-up shot."
"A joyful, playful Corgi running and frolicking in a vibrant park during sunset. The Corgi has a cheerful expression with its tail wagging excitedly as it jumps over small obstacles and chases after a ball. The dog has short legs, a sturdy build, and a fluffy coat. The background showcases a beautiful orange and pink sky with tall grass swaying gently in the breeze. The scene transitions from a wide shot of the park to a close-up of the Corgi, emphasizing its lively actions and the warm, serene atmosphere."
"A person is cycling through a scenic park trail. The rider is wearing a helmet, casual clothes, and sunglasses, pedaling steadily. They are mid-action, leaning slightly forward, with one hand on the handlebars and the other hanging loosely. The environment around them includes lush green trees, blooming flowers, and a winding dirt path. The sun is shining brightly, casting dappled shadows through the leaves. The scene captures a close-up of the rider from a side angle, focusing on their determined expression and the motion of the bicycle wheels."
"A close-up of a person styling their hair with a handheld hair dryer. The person, with a focused expression, holds the hair dryer in one hand and uses a brush in the other to smooth their hair. They are standing in front of a bathroom mirror, which reflects their determined face and the steam from the hair dryer. The background includes a typical bathroom setup with a towel rack and a sink. The person is mid-action, with natural motion captured in a medium shot that emphasizes the interaction between the person and the hair dryer."
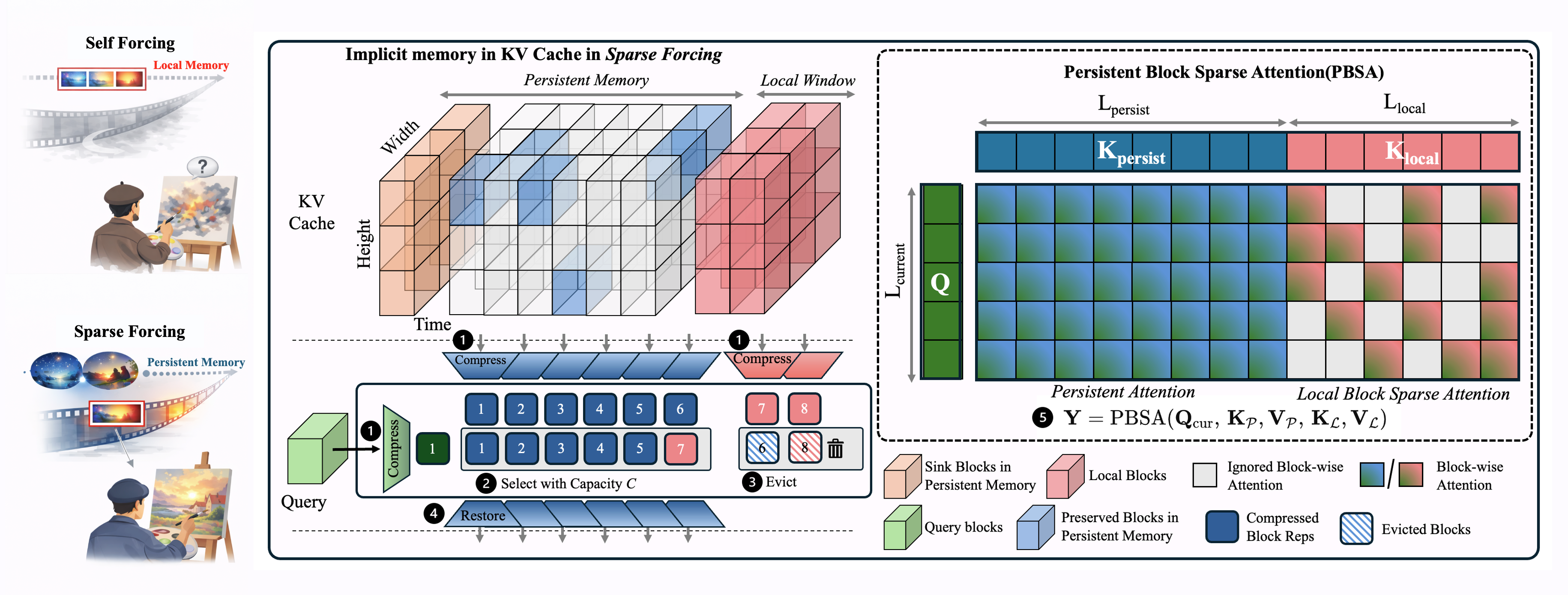
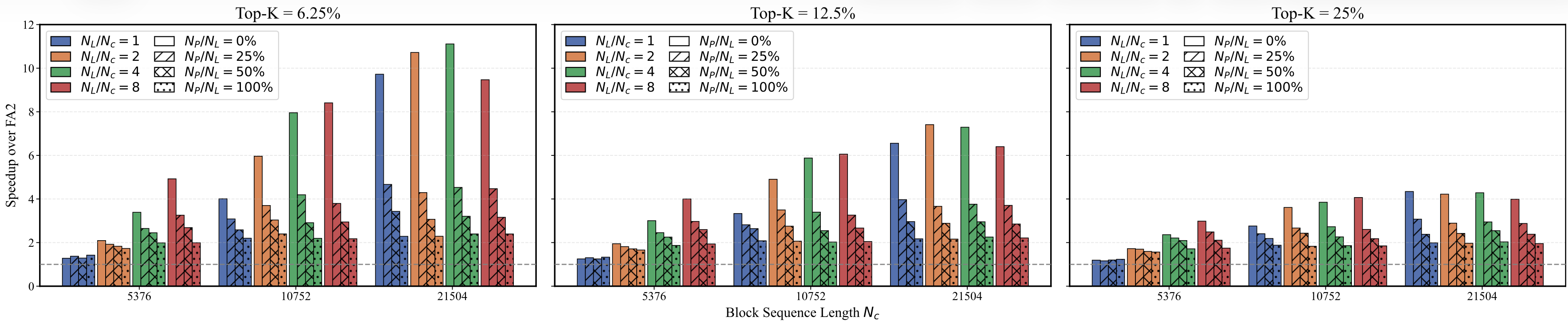
The customized, trainable CUDA kernel implements efficient local block-sparse attention with persistent blocks that maintain globally important context, while supporting composite sparsity patterns and flexible KV-cache management.
Optimized CUDA implementation with Tensor Core utilization for maximum throughput.
Reduced memory footprint through sparse attention patterns and efficient KV caching.
Support for various sparsity patterns: local, sink, and learned top-k selection.
Drop-in replacement for standard attention with full gradient support for training.
from sparse_forcing import SparseForcingAttention
attn = SparseForcingAttention(
total_cache_size=18720,
local_cache_size=9360,
persistent_cache_size=9360,
kv_cache_mode="sparse_forcing",
sparse_kv_block_size=[1, 8, 8],
max_seq_len=32760,
use_local_block_sparse_attn=True,
local_block_sparse_topk_ratio=0.125
)
output = attn(query, key_persistent, value_persistent, key_local, value_local)Comparison with relevant baselines. We compare Sparse Forcing with representative open-source video generation models of comparable scale and resolution. Best results are in bold and second-best results are underlined. ◆: with pretraining; ◇: without pretraining; ♠: [3,4,4] block size; ♣: [1,8,8] block size.
| Model | #Params | Resolution | Throughput (FPS) ↑ | Latency (s) ↓ | Total | Quality | Semantic |
|---|---|---|---|---|---|---|---|
| Diffusion models | |||||||
| LTX-Video (HaCohen et al., 2024) | 1.9B | 768×512 | 8.98 | 13.5 | 80.00 | 82.30 | 70.79 |
| Wan2.1 (Wan et al., 2025) | 1.3B | 832×480 | 0.78 | 103 | 84.26 | 85.30 | 80.09 |
| Chunk-wise autoregressive models | |||||||
| SkyReels-V2 (Chen et al., 2025a) | 1.3B | 960×540 | 0.49 | 112 | 82.67 | 84.70 | 74.53 |
| MAGI-1 (Teng et al., 2025) | 4.5B | 832×480 | 0.19 | 282 | 79.18 | 82.04 | 67.74 |
| CausVid (Yin et al., 2025) | 1.3B | 896×512 | 17.0 | 0.69 | 82.69 | 83.73 | 78.49 |
| Self Forcing (Huang et al., 2025) | 1.3B | 896×512 | 17.0 | 0.69 | 83.88 | 84.60 | 81.01 |
| Sparse Forcing◇♠ | 1.3B | 896×512 | 19.9 | 0.59 | 83.99 | 84.65 | 81.36 |
| Sparse Forcing◇♣ | 1.3B | 896×512 | 18.8 | 0.63 | 83.91 | 84.58 | 81.24 |
| Sparse Forcing◆♠ | 1.3B | 896×512 | 19.9 | 0.59 | 84.14 | 84.84 | 81.39 |
Comparison with baselines on long-horizon generation. ◆: with pretraining; ♠: [3,4,4] block size; ♣: [1,8,8] block size.
| Model | FPS ↑ | Latency/s ↓ | VBench ↑ (T/Q/S) |
|---|---|---|---|
| 20-second length video | |||
| Self Forcing | 14.4 | 0.83 | 82.09 / 82.48 / 80.51 |
| Sparse Forcing◆♠ | 18.3 | 0.65 | 82.68 / 83.13 / 80.87 |
| Sparse Forcing◆♣ | 17.9 | 0.67 | 82.31 / 82.64 / 81.01 |
| 1-minute length video | |||
| Self Forcing | 13.9 | 0.87 | 78.93 / 79.48 / 76.70 |
| Sparse Forcing◆♠ | 18.0 | 0.66 | 81.96 / 82.25 / 80.82 |
| Sparse Forcing◆♣ | 17.6 | 0.67 | 81.67 / 82.17 / 79.67 |
Pre-trained model checkpoints will be released.
Source code and training scripts will be released.
@article{xu2026sparseforcing,
title={Sparse Forcing: Native Trainable Sparse Attention for Real-time Autoregressive Video Generation},
author={Xu, Boxun and Du, Yuming and Liu, Zichang and Yang, Siyu and Jiang, Ziyang and Yan, Siqi and Saha, Rajasi and Pumarola, Albert and Wang, Wenchen and Li, Peng},
journal={pending},
year={2026}
}This work builds upon the excellent open-source implementations of CausVid, Wan2.1, Self-Forcing, and FastVideo. We thank the authors for making their code publicly available.